OpenAIRE workflows¶
- Table of contents
- OpenAIRE workflows
Introduction¶
The OpenAIRE technological infrastructure provides aggregation services capable of collecting content from data sources on the web in order to populate the so-called OpenAIRE Information Space, a graph-like information space describing the relationships between scientific articles, their authors, the research datasets related with them, their funders, the relative grants and associated beneficiaries. By searching, browsing, and post processing the graph, funders can find the information they require to evaluate research impact (i.e. return of investment) at the level of grants and funding schemes, organized by disciplines and access rights, while scientists can find the Open Access versions of scientific trends of interest. The OpenAIRE Information Space is then made available for programmatic access via several APIs (Search HTTP APIs, OAI-PMH, and Linked Open Data), for search, browse and statistics consultation via the OpenAIRE portal, and for data sources with the Literature Broker Service.
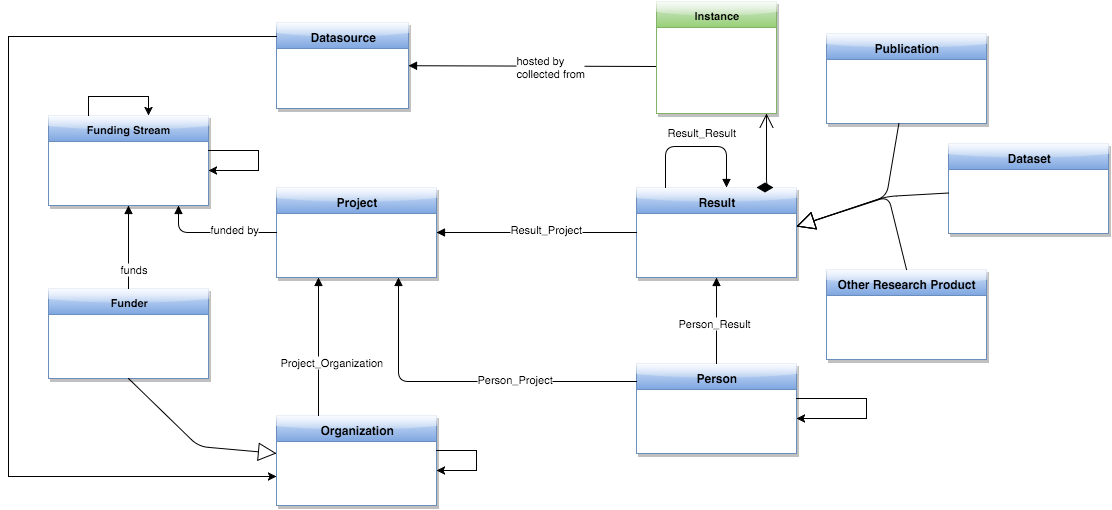
Figure 1 OpenAIRE2020 core data model.
The graph data model is inspired by the standards for research data description and research management (e.g. organisations, projects, facilities) description provided by DataCite and CERIF, respectively. Its main entities are Results (datasets and publications), Persons, Organisations, Funders, Funding Streams, Projects, and Data Sources:
Results are intended as the outcome of research activities and may be related to Projects. OpenAIRE supports two kinds of research outcome: Datasets (e.g. experimental data) and Publications (other research products, such as Patents and Software will be introduced). As a result of merging equivalent objects collected from separate data sources, a Result object may have several physical manifestations, called instances; instances indicate URL of the payload file, access rights (i.e. open, embargo, restricted, closed), and a relationship to the data source that hosts the file (i.e. provenance).
Persons are individuals that have one (or more) role(s) in the research domain, such as authors of a Result or coordinator of a Project.
Organisations include companies, research centers or institutions involved as project partners or that are responsible for operating data sources.
Funders (e.g. European Commission, Wellcome Trust, FCT Portugal, Australian Research Council) are Organizations responsible for a list of Funding Streams (e.g. FP7 and H2020 for the EC), which are strands of investments. Funding Streams identify the strands of funding managed by a Funder and can be nested to form a tree of sub-funding streams (e.g. FP7-IDEAS, FP7-HEALTH).
Projects are research projects funded by a Funding Stream of a Funder. Investigations and studies conducted in the context of a Project may lead to one or more Results.
Data Sources, e.g. publication repositories, dataset repositories, CRIS systems, journals, publishers, are the sources on the web from which OpenAIRE collects the objects populating the OpenAIRE graph. Each object is associated to the data source from which it was collected. More specifically, in order to give visibility to the contributing data sources, OpenAIRE keeps provenance information about each piece of aggregated information. Since de-duplication merges objects collected from different sources and inference enriches such objects, provenance information is kept at the granularity of the object itself, its properties, and its relationships. Object level provenance describes the origin of the object consisting of the data sources from which its different manifestations were collected. Property and relationship level provenance tells the origin of a specific property or relationship when inference algorithms derive these (e.g. algorithm name).
Workflows overview¶
The subsequent sections describes the OpenAIRE workflows, intended as both automated and human activities aimed to:- Aggregate content, i.e. metadata and fulltext;
- Information space population;
- Deduplication
- Inference
- Information space provision & monitoring
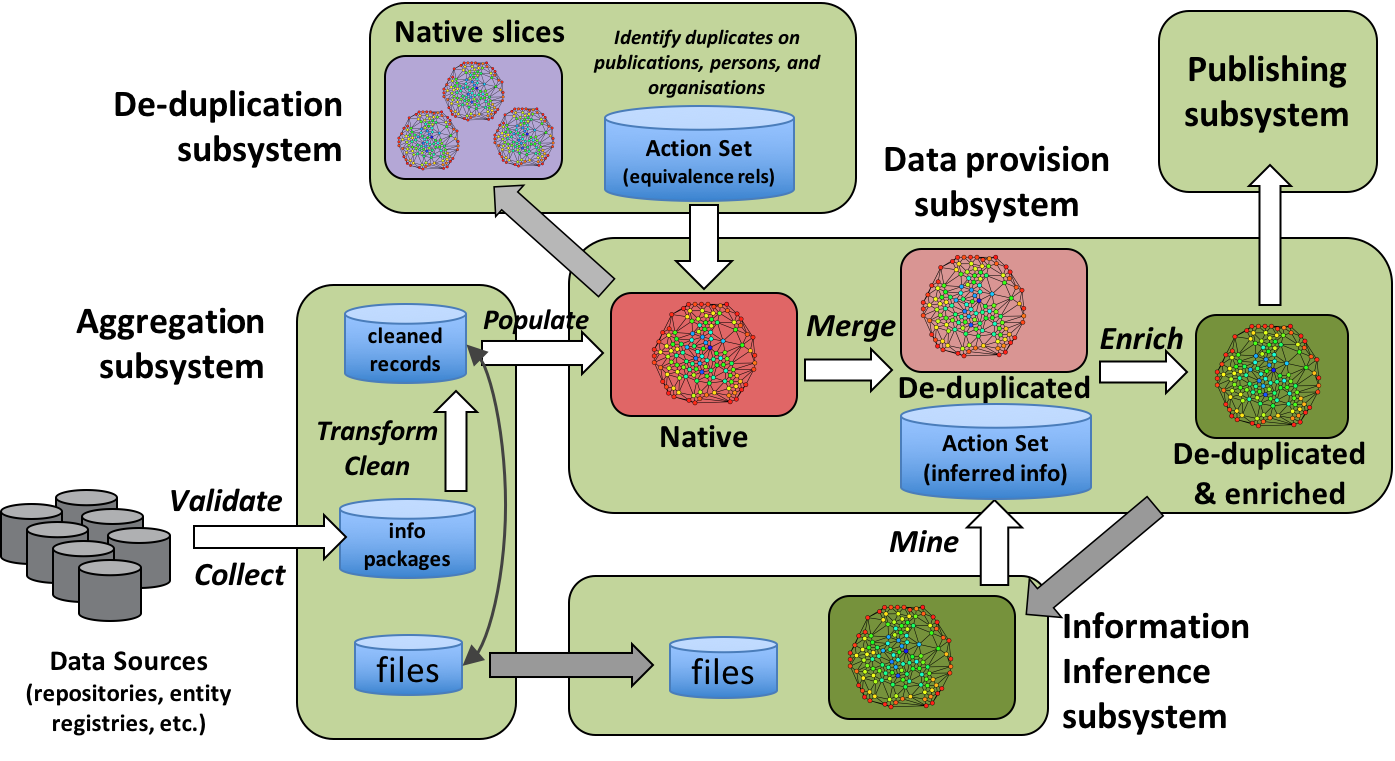
Figure 2 OpenAIRE2020 workflows overvirew.
Content aggregation workflow¶
The OpenAIRE aggregation services support data curators in supervising the content aggregation activity. This consists of (i) registration of a new data source, (ii) validation of its content with respect to the OpenAIRE guidelines, (iii) configuration of existing data sources in terms of access parameters and workflow scheduling (collection and transformation), (iv) monitor the workflow executions to identify common errors that might interrupt the aggregation activity. A given data source can provide a number of different APIs, the typical case assumes an oai-pmh api, and a fulltext download api.

Figure 3 OpenAIRE2020 datasource manager administration user interface.
Metadata aggregation¶
Objects and relationships in the OpenAIRE graph are extracted from information packages, i.e. metadata records, collected from web accessible sources of the following kinds:
Institutional or thematic repositories. Information systems where scientists upload the bibliographic metadata and PDFs of their articles, due to obligations from their organization or due to community practices (e.g. ArXiv, EuropePMC);
Open Access Publishers. Information system of open access publishers or relative journals, which offer bibliographic metadata and PDFs of their published articles; CRIS (Current Research Information Systems) are adopted by research and academic organizations to keep track of their research administration records and relative results; examples of CRIS content are articles or datasets funded by projects, their principal investigators, facilities acquired thanks to funding, etc.;
Data archives. Information systems where scientists deposit descriptive metadata and files about their research data (also known as scientific data, datasets, etc.); data archives are in some cases supported by research and academic organizations and in some cases supported by research communities and/or associations of publishers;
Entity Registries. Information systems created with the intent of maintaining authoritative registries of given entities in the scholarly communication, such as OpenDOAR3 for the institutional repositories or re3data.org for the data repositories;
Aggregator services. Information systems that, like OpenAIRE, collect descriptive metadata about publications or datasets from multiple sources in order to enable cross-data source discovery of given research products; aggregators tend to be driven by research community needs or to target the larger audience of researchers across several disciplines; examples are DataCite for all research data with DOIs as persistent identifiers, BASE for scientific publications, DOAJ for Open Access journals publications.
Fulltext aggregation¶
The fulltext aggregation workflow has a twofold goal: (i) collect and store the fulltext files described by publication metadata records, and (ii) preserve the association between the fulltext file and its corresponding metadata record. This association plays a crucial role in the inference workflow as it determines the possibility to correctly associate the inference results produced by mining a given fulltext, to the corresponding metadata record.
While in case of metadata records describing publications the aggregation system can rely on well established formats and exchange protocols, in case of fulltext the aggregation system often needs to crawl the landing page included in the metadata record to discover the link pointing to the fulltext. To cope with this the fulltext collection system was designed to be extensible with new download plugins, capable to manage specific cases or to be configured to recognise specific url patterns.
As for today the OpenAIRE service in charge to persist the fulltext files counts roughly 4.5 million of fulltext files responding to different formats: PDF, JATS, HTML.
Information space population¶
An information package collected from external data sources is a file in some machine readable format (e.g. XML, JSON), which contains a data source-assigned identifier (mandatory) and information (e.g., properties) relative to a primary object, of a given object type (entity). In some cases, an information package may be relative to a set of primary objects, as in the case of CSV files. Beyond the primary object, an information package may contain information (but not necessarily the identifier) relative to other objects (of likely different types), called derived, which must be directly or indirectly associated with the package primary object.
From the data sources mentioned above, the aggregation services collect metadata records (mainly XML files, but also CSV files, JSONs, structured HTML responses, etc.) and perform two actions: (i) extracting from metadata records OpenAIRE objects and relationships to feed the information space graph and (ii) harmonizing object properties to make them conforming to the OpenAIRE data model types. For example, as shown in the figure above, a Dublin Core bibliographic metadata record describing a scientific article will yield one OpenAIRE publication object and a set of OpenAIRE person objects (one per author) with relationships between them.
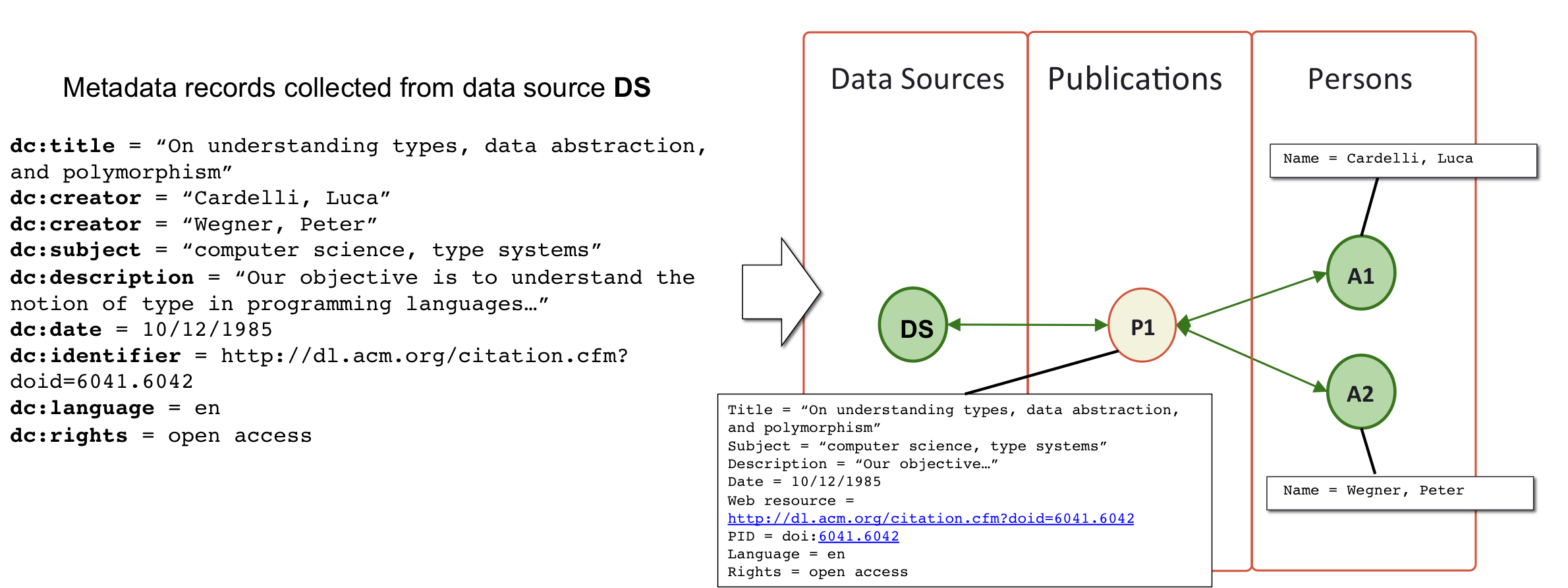
Figure 4 OpenAIRE2020 Information space population.
Deduplication workflow¶
OpenAIRE deduplication requirements are derived from the high heterogeneity, multidisciplinarity, and dynamicity of the metadata records it aggregates, as well from the considerable size of the information space graph itself.
Candidate identification¶
In this scenario, matching all pairs of publications to identify the duplicates is by no means intractable as today the aggregation system counts more than 17M publications. To address this issue, candidate identification is the phase entitled of providing the heuristics and technological support necessary to avoid such "brute force" solution. Candidate identification is solved using clustering techniques based on functions that associates to each object, out of its properties, one or more key value to be used for clustering. The idea is that objects whose keys fall in the same cluster are more likely to be similar than across different clusters. This action narrows the pairwise matching of objects within the clusters, thereby reducing the complexity of the problem. As a general rule the definition of a good clustering function for deduplication must avoid false negatives (i.e. making sure that obvious duplicates fall in the same cluster), avoid false positives (i.e. making sure that clearly different objects fall in the same cluster), and make the number of matches to be tractable by the technology at hand. The definition of a good clustering function for deduplication of publications starts from the properties available in the publications metadata. From the analysis of the publication properties the only property to be always present and informative enough is the Title. Clustering objects starting from a publication Title may be done according to different strategies, which avoid or tolerate minor differences in the titles, typically caused by typos or the partial/full presence of words. Some examples are:removing stop words, blank spaces, etc.;
- lower-casing all words;
- using combination of prefixes or postfixes of title words;
- using ngrams of relevant words;
- using hashing functions.
Using any of these strategies has implications that depend on the features of titles in the information space. For example, the heavy presence of short titles (consisting at most of a few short words) may find in the hashing function a better solution than using prefixes of words. On the other hand, the adoption of high performance technologies may allow for a more greedy approach, which allows for more matches to be performed hence avoid false negatives. The OpenAIRE information space is very heterogeneous as both data sources and disciplines behind publications are of different kinds. As a consequence the preferred approach is the ones that combines the first letters of words (like an acronym) into a clustering key and the last letters of words into another clustering key. The approach is quite typo-safe and proves to exclude the majority of false negatives, on the other hand it includes false positives, which should be excluded with the subsequent detailed similarity match.
Candidate matching¶
The method described above is known in record linkage literature as Blocking, and to further narrow the number of pairwise comparisons can be followed by the so called Sliding Window method. The sliding window is based on the idea that objects in the cluster are ordered in such a way the chance that similar objects are closer in the ordering is higher. Objects in the cluster are then pairwise matched only if they are part of the same sliding window of length K. When all objects have been matched, the sliding window is moved to the next element of the ordering and a new set of pairs is matched. Sliding windows introduce false negatives, since they exclude from the match objects in the same cluster, but control performance by giving an upper bound to the number of matches in each cluster.
In order to define a solid candidate matching function, we need to identify which properties are most influential in the matching process, that is best contribute to establishing object equivalence by introducing lower computational cost, while allowing clear cut decisions, and are often present in the publications. Surely the publication Title is again a good choice, it is present in (almost) all objects and consist of a relatively short text, which can be fast and reliably processed by known string matching functions. In general, if the titles of two publications are not "enough" similar (according to a given threshold) then no other property-to-property match may revise this decision. Of course title equivalence is not enough as one of the following cases may occur:- Very short titles, composed of few, commonly used words may lead to obvious equivalence; e.g. the title "Report on the project XYZ" may be recurrent, the only difference being the name "XYZ" of the project;
- Recurrent titles; e.g. the title "Introduction" of some chapter is very common and introduces ambiguity in the decision;
- Presence of numbers in titles of different published works; e.g. the title "A Cat's perspective of the Mouse v2" is likely referring to a publication different from "A Cat's perspective of the Mouse", but not different from "A Cat perspective of the Mouse";
As a consequence, the decision process must be supported by further matches which may strengthen the final conclusion, possibly based on one or more of the following publication properties:
Author names, Date of acceptance, abstract, language, subjects, pid, are all publication features that could contribute to the matching on different levels, however their contribute mostly depend on the data quality. In the OpenAIRE case the PIDs are significantly contributing to the matching process. Unluckily they're present in a subpart of our publication records (between 30-40%), but on the bright side they contribute allowing to take strong decisions on the equivalence of two publications: If 2 publications provide the same DOI they're indeed duplicates. The contrary is valid as well: if 2 publications provide different DOIs, they're not the same publication (and there is no need to further compare other properties). Therefore, a similarity function, based on the availability of certain properties can take straightforward decisions on equivalence or difference between publications, while in other cases can only come up with a rank of confidence that depends on the availability and weights of the properties above.
Graph disambiguation¶
Duplicate identification terminates providing a set of pairs of duplicated publications. As OpenAIRE maintains a graph of publications, persons, projects, data sources, and organisations, in order to disambiguate such a graph, the requirements in OpenAIRE is that duplicates should be hidden to be replaced by a "representative object" which points to the duplicates it represents (and vice versa) and becomes the hub of all incoming and outgoing relationships relative to these objects. As a result, the graph will be disambiguated but still keep track of its original topography. As a consequence, graph disambiguation consists of two phases: duplicate grouping and duplicates merging. Keeping track of the records merged behind a representative is what allows data curators to measure the duplicates percentage for a given datasource (~18K duplicate publications in NARCIS).
Grouping duplicates requires the identification of the connected components formed by the equivalence relationships identified by duplicate identification. Merging the groups of duplicates requires instead the creation of a representative object for each connected component (or group of duplicates) and the propagation towards this new object of all incoming and outgoing relationships of the object it merges. Both actions have serious performance implications, which depend on the topography of the graph (e.g. fragmentation of graph, edge distance of objects in the graph, number of the duplicates). For example, the number of duplicated publications depends on the replication of the publication across different data sources, e.g. institutional repository of the author, thematic repository, and a number of aggregators, but it is in general not very high (e.g. co-authors, each depositing in their respective institutional repositories which are in turn harvested by OpenAIRE).
Updated by Claudio Atzori over 9 years ago · 11 revisions