Aggregation subsystem » History » Revision 19
« Previous |
Revision 19/22
(diff)
| Next »
Alessia Bardi, 06/08/2015 06:08 PM
updated figure for data source scope strategy
Aggregation subsystem¶
OpenAIRE infrastructure collects objects from a set of data sources of different typologies, e.g. repositories, CRISs, dataset archives, aggregators, entity registries, journals. All these contain information relative to different interrelated objects of the OpenAIRE data model and expose them via a specific protocol and exchange format. In general, data sources expose information packages (i.e. metadata records) describing a primary object and possibly other sub-objects. For example, an OpenAIRE compliant repository delivers information packages (i.e., metadata records) which contain information about a publication result object, but also the (author) persons who created such result, the projects funding such result, etc. The aggregation system is in charge of collecting heterogeneous information packages and transforming them onto internal homogeneous formats, which the data provision subsystem can directly transform onto the native information space graph. To this aim, the aggregation system has to cover the following responsibilities:
- managing an arbitrary large set of data sources;
- define, monitor, and execute ingestion workflows for all data sources, based on their typology (e.g. repository, journals, aggregators), protocol (e.g. OAI-PMH, FTP, JDBC, local file system), exchange format (e.g. XML, CSV, JSON), primary entity type (e.g. publication, dataset, projects).
- implement specific stateless identifier policies: guaranteeing that if the same objects or relationships are collected more than once from the same data sources, they will be assigned the same identifier in OpenAIRE.

Figure 1 – Information packages and mapping onto native objects
The following sections will introduce the notions of:
- Information packages and ingestion workflows;
- How to assign a stateless (and permanent) identifiers to the primary objects when they enter the information space;
For each of these aspects, an explanation of the problem, an extension of the data model to handle the problem, and, where necessary, a solution to the problem using the updated model are provided.
Information packages¶
In OpenAIRE objects are collected from external data sources in the form of information packages. In particular, an information package is a file in some interpretable format (e.g. XML, JSON), which contains a data source-assigned identifier (mandatory) and information (e.g., properties) relative to a primary object, of a given object type (entity). In some cases, an information package may be relative to a set of primary objects, as in the case of CSV files. Beyond the primary object, an information package may contain information (but not necessarily the identifier) relative to other objects (of likely different types), called sub-objects, which must be directly or indirectly associated with the package primary object. Figure 1 shows an example of an information package whose primary object is 1: for example, an information package from OpenDOAR is relative to a repository data source object and can be identified by the relative OpenDOAR identifier. Its sub-objects are those from 2 to 6: for example, an OpenDOAR package also contains information about the organization object responsible for the repository data source.
Ingestion workflows¶
We call ingestion workflow the process that takes the information package from a data source and transforms them onto internal OpenAIRE entity formats. OpenAIRE internal formats are of three main kinds: OAF for publications, DFM for datasets, and PFM for projects. These are currently the only primary object types being harvested from data sources, other internal formats will be defined if necessary.
In general a workflow is therefore dependent on:
- The data source typology;
- The access method, namely (i) protocol required to get the data (e.g., OAI-PMH, JDBC, FTP) and (ii) relative access configuration (e.g., entry point, parameters, etc.);
- The primary object type of the information packages, which implies an internal OpenAIRE format;
- The exchange format of the information package at hand, which implies a mapping that maps the structure and semantics of information packages onto the corresponding OpenAIRE internal format.
To be sustainable, the OpenAIRE infrastructure requires data sources of a given typology to comply to specific export OpenAIRE guidelines. Guidelines are available for publication repositories (also apply to aggregators of repositories, journals, and aggregator of journals), data repositories (also apply to aggregators of data repositories), and CRIS systems. Respectively, such data sources must export information about publications, datasets, and publication/datasets/persons/projects respectively. Suggested protocols are OAI-PMH and FTP, but different (HTTP-proprietary) protocols can also be managed. Guidelines are extremely important, since assuming a uniform incoming format for given primary objects moves the complexity of ingestion workflows at the semantic level of the mappings. For other typologies of data sources, namely entity registries, specific workflows must be defined, as data sources changes considerably in the way they export content. In such cases the workflows will also define structural mapping from a data source information package format to the internal OpenAIRE format.
Note that data sources of the same typology may deliver information packages relative to different primary entity types and this will happen from different data source access points (in data source profiles, these are called APIs). For example, CRIS systems may expose through OAI-PMH both publication or project primary objects, and in such cases they will be associated two distinct ingestion workflows.
| Data Source Typology | Primary Object Type | Ingestion Format | OpenAIRE internal format | Description |
| publication repository, journal, aggregators | Publication (Result) | Dublin Core qualified (OpenAIRE Guidelines for Literature Repositories) | OAF | |
| data repository | Dataset (Result) | DataCite qualified (OpenAIRE Guidelines for Data Archives) | DFM |
Identity of original entities¶
Original objects must be assigned a unique “stateless” identifier. The data sources of such objects are not under the OpenAIRE infrastructure control and may in any moment decide to delete, update, or add new objects or relationships between them. Hence, it is particularly important to make sure such identifiers are generated from the incoming information packages in a stateless and stable way that is “if the same objects enters the information space at different times, it will be assigned the same identifier”. To this aim, the OpenAIRE infrastructure constructs indentifiers for primary objects and sub-objects in an information package by combining three levels of scope: data sources, primary objects, and sub-objects of such primary objects. More specifically:
- Infrastructure scope: all data sources are registered and assigned a unique identifier in OpenAIRE; data sources are also assigned a readable unique namespace prefix, which will be used to prefix identifiers of objects collected from the data source;
- Data source scope: information packages from the same data source contain primary objects with an identifier which is unique in the context of the data source.
- Primary object scope: information packages may contain a number of sub-objects relative to the primary object; unlike primary objects, sub-entities may not necessarily come with an identifier (data source scope) and can be generally uniquely identified in the scope of the primary object based on their descriptive properties. The process of identification of such “unique information” is very much dependent on the given information package structure and data source.
Identity of primary objects¶
The process of generation of stateless identifiers for primary objects is always based on a data source scope strategy. Independently of the workflows, the type of entity, and the data source kind, primary objects identifiers are always obtained by concatenating the "namespace prefix of the data source" with the MD5 of the identifier of the primary object as exposed by the datasource (the "original id" of the primary object):
openaireID = namespacePrefix:MD5(original id of the primary object)
Identity of sub-objects¶
Assigning identifiers to sub-objects can be performed following different strategies, some more “optimistic” and some more “pessimistic” about the ability of finding unambiguous “unique information” about sub-objects in the information package. The strategies OpenAIRE applies vary based on the data source, the object types (entity) and the relative information packages structure. Table X summarizes the different cases considered in OpenAIRE:
- Data source scope strategy: Sub-objects with the same “unique information” are collapsed in the same object but only within the same data source scope. The Deduplication sub-system will identify and solve (i.e. split) possible object "overloads" in a second stage. This is the case for person objects originated from institutional repositories, where the optimistic assumption is that homonyms (two different authors with the same name) are rare in one institutional repository.
openaireID = nameSpacePrefix::MD5(uniqueInformation)
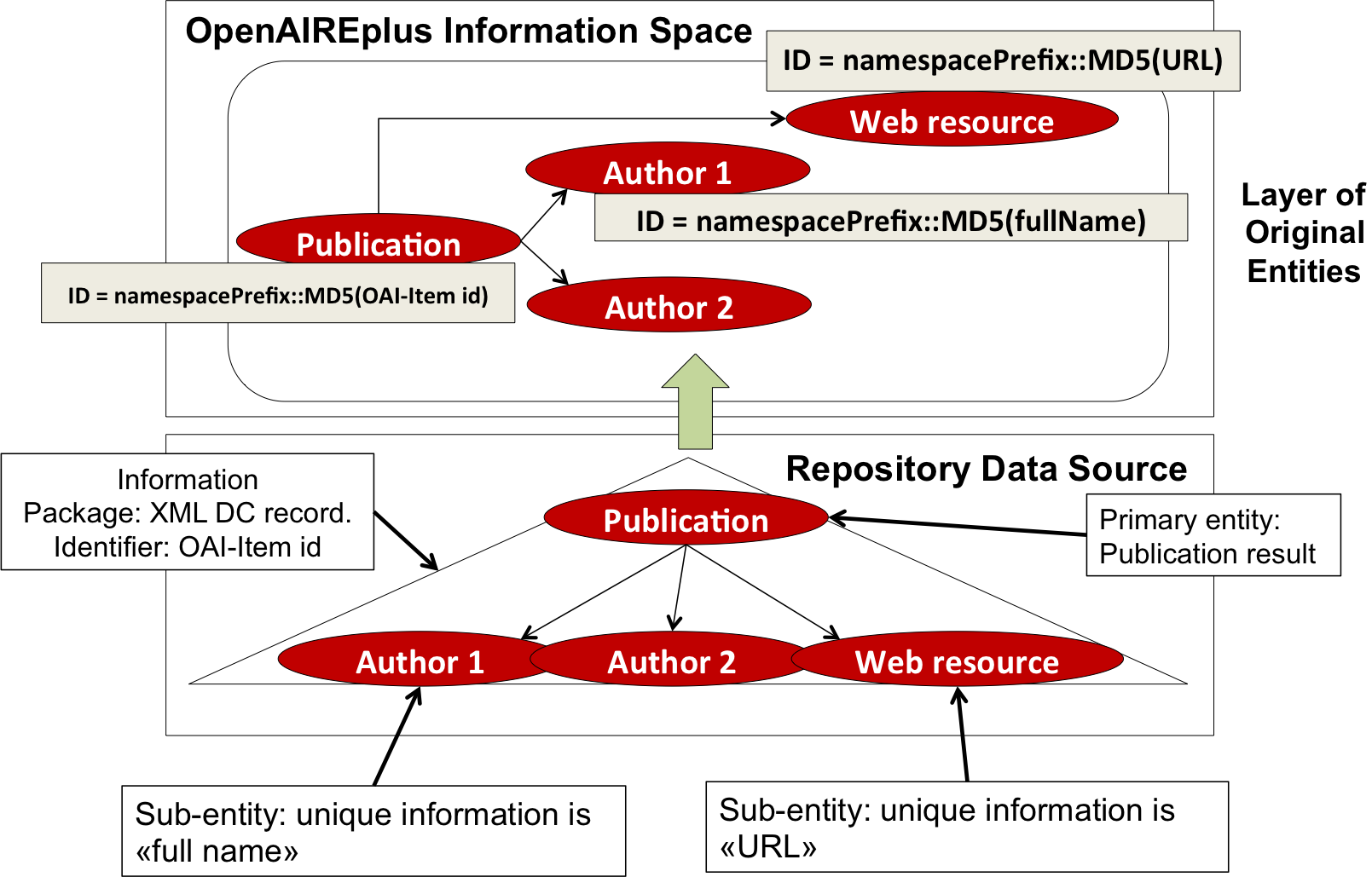
Figure 2 – Assigning unique identifiers to sub-entities: data source scope
- Primary entity scope strategy: Sub-objects with the same “unique information” are collapsed in the same object but only within the same primary object scope (see Figure 9). The Deduplication sub-system will identify and solve (i.e. merge) possible object "duplicates" in a second stage.
openaireID = nameSpacePrefix::primaryObjectOpenaireID::MD5(uniqueInformation)
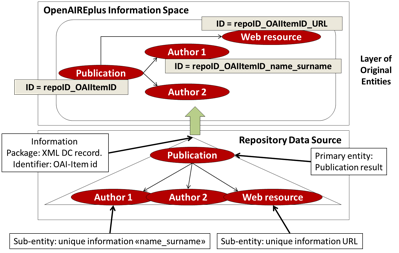
Figure 3 – Assigning unique identifiers to sub-entities: primary entity scope
Table 1: Strategies for identifier assignment in OpenAIRE
| Datasource typology | Collected primary object type | Primary object original identifier | Primary object id | Collected sub-objects types | Sub-object unique information | Sub-object id | Sub-object id generation strategy |
| Publication repository [1] | Publication | oai identifier (oaiID) |
namespacePrefix::MD5(oaiID) |
Person | //dc:creator |
namespacePrefix::MD5(//dc:creator) |
Data source scope strategy |
| Aggregator of Publication repositories, Aggregator of journals, Thematic Publication Repositories, Journal | Publication | oai identifier (oaiID) |
namespacePrefix::MD5(oaiID) |
Person | //dc:creator |
namespacePrefix::MD5(//dc:creator) |
Primary entity scope strategy |
| Data repository | Dataset | oai identifier (oaiID) |
namespacePrefix::MD5(oaiID) |
Person | //dc:creator |
namespacePrefix::MD5(//dc:creator) |
Data source scope strategy |
| Aggregator of data repository | Dataset | oai identifier (oaiID) |
namespacePrefix::MD5(oaiID) |
Person | //dc:creator |
namespacePrefix::MD5(oaiID:://dc:creator) |
Primary entity scope strategy |
| Entity Registry | Datasource | ID: depends on the entity registry |
namespacePrefix::MD5(ID) |
Organization | orgID: depends on the entity registry |
namespacePrefix::MD5(orgID) |
Data source scope strategy |
| Projects | ID: depends on the entity registry |
namespacePrefix::MD5(ID) |
Organization | orgID: depends on the entity registry |
namespacePrefix::MD5(orgID) |
Data source scope strategy | |
| Person | personID: depends on the entity registry |
namespacePrefix::MD5(personID) |
Data source scope strategy | ||||
| CRIS system | Publication | COMING SOON | COMING SOON | COMING SOON | COMING SOON | COMING SOON | COMING SOON |
| Dataset | COMING SOON | COMING SOON | COMING SOON | COMING SOON | COMING SOON | COMING SOON | |
| Person | COMING SOON | COMING SOON | COMING SOON | COMING SOON | COMING SOON | COMING SOON | |
| Project | COMING SOON | COMING SOON | COMING SOON | COMING SOON | COMING SOON | COMING SOON |
[1] For publicaton repositories, the default strategy has the "Data source scope". However, in cases of very large publication repositories, the "Primary entity scope" strategy might be more more appropriate. The OpenAIRE aggregation infrastructure enables to override the default strategy for specific datasources, whenever needed.
Updated by Alessia Bardi almost 11 years ago · 19 revisions