D6.1 OpenAIRE Specification and Release Plan (v1, 28th of February 2015)¶
- Table of contents
- D6.1 OpenAIRE Specification and Release Plan (v1, 28th of February 2015)
Introduction¶
The aim of this document is to explain in detail how the overall software release plan as detailed in the DoW (Figure 1) will be accomplished by the technical partners. For this, it will illustrate the plan of design, development, testing, and integration into production of the infrastructure services to be delivered in WP6, WP8, WP9, and WP10 (Figure 2: note that WP7 will not contribute to the operational services). The plan’s technical activities will be supervised and led by CNR and carried out across the technical partners CNR, CERN, UoA, ARC, ICM, UBONN, and UNIBI, in synergy with the scientific partners EBI, JISC, COUPERIN, DANS, UMINHO.
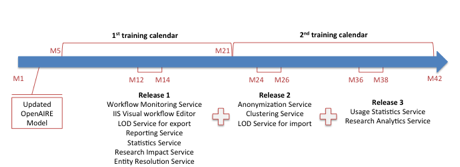
Figure 1 OpenAIRE2020 technical and training programme timeline overview.
The OpenAIREplus infrastructure service software will be delivered in three releases corresponding to the milestones illustrated in Table 1. Each release will follow a cycle of pilot › testing › integration› deployment schedule that lasts 2 months, and will incrementally containing new services developed in WP8, WP9, and WP10. The plan will describe the parallel activities envisaged to achieve these objectives. In order to interpret this structure and roadmap, in the next section we shall introduce an overview of the functional requirements of the OpenAIRE infrastructure in OpenAIRE2020, given in terms of the new end-user interaction scenarios and data management issues.
Table 1 - OpenAIREplus: Deliverables and Milestones
| _ Date_ | Phase | Milestone/deliverable | Services/functionalities |
| M5 | OpenAIREplus data model definition | D8.1 | |
| M14 | Release 1 | M6.2 | The release will incorporate all services that are production ready by M12: LOD v1, Resarch Impact v1, Data Flow Montoring v1, Innovative portal services v1, Stats and visualization v1, Zenodo v2, Visual workflow editor |
| M26 | Release 2 | M6.4 | The release will incorporate all services that are production ready by M24: LOD v2, Research Impact v2, Data Flow Monitoring v2, Innovative portal services v1, Stats and visualization v1, Zenodo v2, data-citation interlinking prototype, anonymization service, clustering agorithms, entity resolution algorithms |
| M38 | Release 3 | M6.5 | The release will incorporate all services that are production ready by M36: LOD v3, Research Impact v3, Data Flow Monitoring v3, Innovative portal services demonstration, OA Broker Service, Mining training algorithms, Usage Statistics Services, Map of academic relationships |
Figure 2 – Research Joint Activities: WP6, WP7, and WP8
Functional Requirements¶
In this section we shall present the main functionalities to be realized in OpenAIRE2020. To this aim, we shall first introduce the status of the OpenAIRE infrastructure, on top of which OpenAIRE2020 will provide extensions.
OpenAIRE infrastructure today (28th of February 2015)¶
The OpenAIRE system implements an advanced data infrastructure, whose purpose is (i) enabling the collection of heterogeneous data, (ii) aggregation and processing of such data to generate a uniform information space, and (iii) offering access to the information space.
Collection of content from data sources OpenAIRE collects and integrates the following data source typologies:- Data and publication repositories: metadata records from institutional repositories, data repositories, and CRIS systems that comply to the OpenAIRE guidelines (http://guidelines.openaire.eu) and to the OpenAIRE dara acquisition policies (https://www.openaire.eu/openaire-s-content-acquisition-policy/document-details).
- Entity registries: metadata records from entity registries (authority list maintainers):
- Project funding information from the following databases: EC CORDA database (FP7 projects), WellCome Trust, and FCP (Portugal Ministry), which include information about projects and participants.
- Publication repository information from the OpenDOAR directory.
- Data repository information from the re3data.org directory.
- Document files: publication files for mining from data sources authorizing this process.
- Human claims: end users can “claim”, i.e. ingest, publication metadata records (via DOI or ORCID identifier), together with access rights and references to project funding (or EGI initiative). End-users can also claim relationships between publications and datasets.
- Zenodo: The OpenAIRE infrastructure supports the Zenodo repository whose purpose is to offer publication and data repository management functionalities for those authors who do not have a repository of reference and are willing to respect the OA mandates of the EC. Zenodo is registered into the infrastructure as a data and publication OpenAIRE compliant repository, hence all its content is aggregated in the information space.
- Validation: to be regularly aggreagated into the OpenAIRE information space, data sources must export metadata according to the indications provided by the guidelines. The infrastructure offers validation services capable of evaluating the degree of conformance of a repository and return useful feedbacks. Once the data source is validated, its managers can register it to the OpenAIRE infrastructure and make it available for data collection.
Cleaning and enrichment of aggregated content
- Cleaning: the infrastructure operates a metadata harmonization framework that supports data curators at defining mapping rules between records collected from the data sources described above and the graph structure of the information space. Incoming records are mapped into sub-graphs and their properties are harmonized to match the OpenAIRE data model semantics (e.g., vocabulary conversion, format conversion).
- Mining: the infrastructure operates a mining framework that takes as input the OpenAIRE information space and the relative documents in order to identify missing properties and relationships about the entities. Tools allow for (i) extracting text from several document formats (PDF, HTML, XML) and (ii) run a set of inference modules, which can be dynamically plugged in or modified to match new configurations. Current modules include: classification, citation, similarity, publication-datasets relationships, publication-project relationships, publication-EGI community.
- Statistics: the infrastructure operates services for the calculation and caching of elaborated statistics over the graph, in order to offer immediate access to such numbers. Statistics regard Open Access as well as impact in terms of publications with respect to projects, funding schemes, research initiatives.
- De-duplication: the infrastructure operates de-duplicaiton services that allow data curators to define/refine algorithms for the identification of duplicates across tens of millions of publications, organizations, and authors. The algorithms also take care of the redistribution of relationships within the graph.
- Discovery: the portal implements advanced search and browsing mechanisms over the graph-structured information space; access to statistics by funder and for EGI (European Grid Infrastructure).
- Claims: End-users can manage the set of their claim actions.
- Regisitration and validation of data sources: data sources managers can register their repository, CRIS system, journal, aggregator to the infrastructure and validate their content with respect to the guidelines.
- APIs: APIs allow for bulk, selective, or random access to the OpenAIRE information space. Specifically: HTTP rest queries and OAI-PMH APIs.
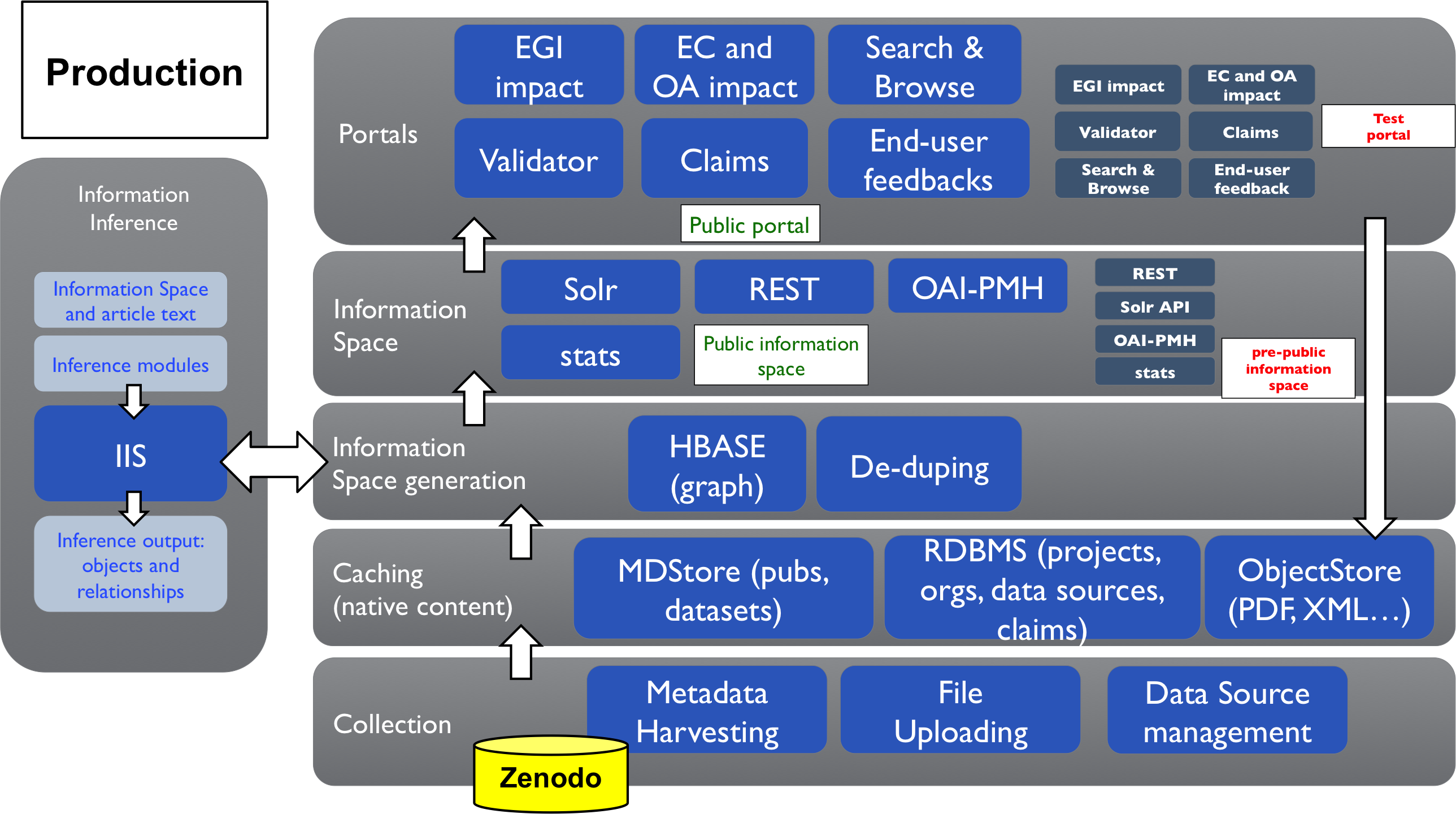
Figure 3 - OpenAIRE high-level architecture as is today
OpenAIRE infrastructure in OpenAIRE2020¶
OpenAIRE2020 will extend the OpenAIRE infrastructure with a number of functionalities enhancing the way the information space is populated and accessed. At the end of the project the architecture in Figure 3 will be enhanced to become the architecture in Figure 4.

Figure 4 - OpenAIRE high-level architecture: end of OpenAIRE2020
The project plan has grouped the realisation of new functionalities into the following meta-actions and focused-actions:
Action 1 (WP8) Information Space management This action includes the realization of services for:- Data model update: upgrading the OpenAIRE data model and information space to include further information about licenses (IPRs), software entities, National funding schemes, DMPs
- Linked Open Data Management
- Research Impact Services
- Data flow monitoring
- Data-Literature Interlinking Prototype (from WP7, but strictly connected to information space activities).
- Usage statistics
- Open Access Repository Broker
- Portal: statistics and visualization tools
- Innovative portal services
- Data Anonymization
- Zenodo repository
- New Mining Algorithms: clustering, enhanced document classification, author-organization affiliation parsing, citation sentiment analysis, narrative pattern analysis (identifying division of a PDF document into sections, subsections etc.), domain specific concept mining (gene symbols, chemicals, organisms), extracting links from publications to software and data repositories (BioMedBridges, GitHub, Zenodo, PSI datasets).
- Training algorithms
- Map of academia
In the next section we shall describe the detailed plan for the first 12 months of the project concerning the three actions above.
Release Plan: first year (Feb 2015 - Feb 2016)¶
The release plan is organized into a number of actions whose aim is to accomplish the main actions illustrated in the previous section. Such actions have been identified based on the lines of action to be followed by subgroup of partners in the development of infrastructural services. The first project milestone (see Table 1) will be delivered as a combined and parallel effort of such actions in order to achieve the first-year architecture illustrated in Figure 6.
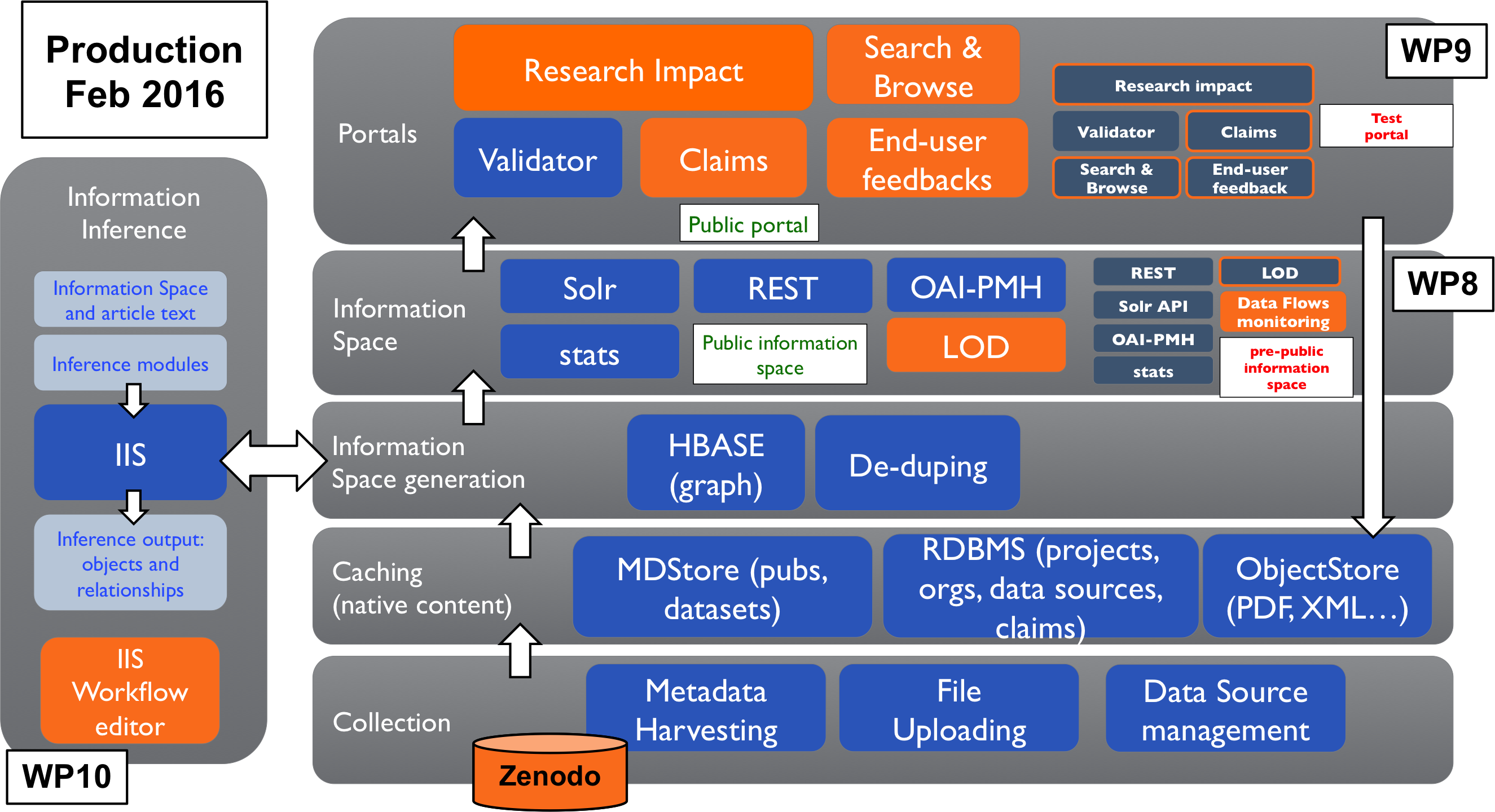
Figure 6 - OpenAIRE high-level architecture: February 2016
Dependencies No particular dependencies among project tasks occur and this notably simplifies the activities, giving partners the possibility to work in parallel without too much conflicts. On the other hand, all services inherently depend on the data model and on its implementation by the information space services, which mainly include the HBASE cluster used for information space graph population and de-duplication. Any change affecting the data model or its “implementation” will inherently affect the other services depending on these, such as portal services, information mining services, and export services (OAI-PMH, statistics, LOD, OA repository broker, etc.). The OpenAIRE data model will be consolidated and release at Month 4, then other upgrades will follow at M18 and M30. Such releases will serve as starting point for potential change of actions in order to realign the services to potential changes in the schema.
Development, BETA, production infrastructures The plan described in the following is made possible by the activities carried out in WP6 which regard the overall software life-cycle: design, development, testing, integration, packaging, and deployment into production. Figure 5 illustrates the development-to-production scenario. CNR is responsible for the installation and maintenance (on-demand) of development infrastructures, where OpenAIRE2020 technical partners can independently or in synergy develop, test and integrate their services. ICM is responsible for the maintenance of the OpenAIRE production and BETA infrastructure, ensuring 24/7’s operation. Tested services are first deployed into the BETA infrastructure, which is supposed to emulate the production environment for final service integration testing and possible end-user validation (for new portal services). The BETA infra can reuse the same inference and de-duplication clusters of the production infrastructure, thereby emulating the “on-line” conditions met by the production system. As such the BETA is not supposed to be used as a development/testing environment, but should only contain the new upgrade ready for the next release.
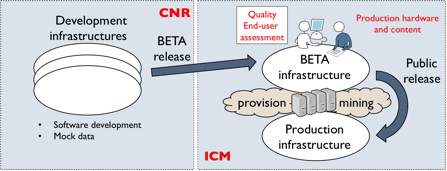
Figure 5 OpenAIRE development, BETA and production infrastructure
The next 12 months are organised in the following actions, which correspond to partial or full accomplishment of the tasks described in the DoW document. The detailed plan for the tasks can be found by clicking on the individual wiki pages.
Action 1 (WP8) Information Space management¶
- T8.1 OpenAIRE data model (Task leader: CNR): available
- T8.2 LOD services (Task leader: UNIBONN): available
- T8.3 Research impact services (Task leader: ARC): available
- T8.4 Data flows and dynamics monitoring services (Task leader: CNR): available
Table 2 - Deliverables and milestones in action 1: first 12 months
| Date | Document type | Document number | Title |
| Apr 2015 | D | D8.1 | OpenAIRE data model |
| Jun 2015 | D | D8.2 | LOD services |
| Jul 2015 | D | D8.3 | Research impact services |
| Sep 2015 | D | D8.4 | Data flows and dynamics monitoring services |
| Dec 2015 | M | M8.1 | LOD services |
| Dec 2015 | M | M8.2 | Research impact services |
| Dec 2015 | M | M8.3 | Data flows and dynamics monitoring services |
Action 2 (WP9) Portal and end-user services¶
- T9.1 OpenAIRE portal and services (Task leader: ARC): to be provided
- T9.2 Stats, reporting, and visualization services (Task leader: ARC): to be provided
- T9.3 Zenodo service (Task leader: CERN): available
Table 3 - Deliverables and milestones in action 1: first 12 months
| Date | Document type | Document number | Title |
| Jun 2015 | D | D9.1 | OpenAIRE portal and services |
| Aug 2015 | D | D9.2 | Stats, reporting, and visualization services |
| Jun 2015 | D | D9.3 | Zenodo service |
| Dec 2015 | M | M9.1 | OpenAIRE portal and services |
| Dec 2015 | M | M9.2 | Stats, reporting, and visualization services |
| Dec 2015 | M | M9.3 | Zenodo service |
Action 3 (WP10) Information mining¶
- T10.1 Visual workflow editor with other internal enhancements (Task leader: ICM): available
- T10.2 Classification and clustering (Task leader: ARC) - start of gathering internal specifications and working on part of the functionality to be delivered
- T10.3 Entity resolution and linking (Task leader: ICM) - start of gathering internal specifications and working on part of the functionality to be delivered
Table 4 - Deliverables and milestones in action 1: first 12 months
| Date | Document type | Document number | Title |
| Aug 2015 (error in DoW: October 2015) | D | D10.1 | Visual workflow editor |
| Dec 2015 | M | M10.1 | Visual workflow editor |
Release Plan: second year (Feb 2016 - Feb 2017)¶
To be defined.
Release Plan: third year (Feb 2017 - Feb 2018)¶
To be defined.
Updated by Mateusz Kobos over 11 years ago · 25 revisions