Actions
Subsystems » History » Revision 6
« Previous |
Revision 6/9
(diff)
| Next »
Paolo Manghi, 29/04/2015 12:21 PM
OpenAIRE infrastructure sub-systems¶
The OpenAIRE infrastructure features a number of sub-systems, dedicated to four main activities:
- Aggregation sub-system: collection of information packages and publication texts (e.g. PDFs, XMLs, HTMLs) from data sources; based on the typology of such packages (e.g. Dublin Core metadata records, DataCite metadata records, CERIF-XML metadata records, proprietary formats), the system transforms them onto "cleaned" metadata records with uniform structure and semantics, matching the specification of the OpenAIRE data model;
- De-duplication sub-system: given as input the native information space graph (as generated by the data provision sub-system), the system identifies duplicates among the objects of the same entity type; for each entity, the system generates a set of similarity relationships between pairs of objects identified as duplicates, which will be used by the data publishing subsystem to generate a disambiguated information space;
- Information inference sub-system: given as input the last public information space graph (disambiguated and enriched by inference in the last round) and the publications full-texts, the system applies a number of mining algorithms (i.e. "modules"); for each mining module the system produces a set (called ActionSet) of inferred information, which will be used by the data publishing sub-system to enrich the information space graph;
- Data provision sub-system: given as input the cleaned metadata records as yielded by the aggregation sub-system, the similarity relationships as (last) yielded by the de-duplication sub-system, and the inference ActionSets as (last) yielded by the information inference sub-system, the data provision system: 1) populates an initial bare-aggregation information space graph, 2) enriches the graph with similarity relationships and runs an object merging algorithm to remove duplicates, 3) enriches the graph with inferred information, 4) instantiates (publishes) the graph over three back-ends serving different use-cases: full-text index, OAI-PMH publisher, PostgreSQL statistics database (a LOD back-end is being developed in OpenAIRE2020).
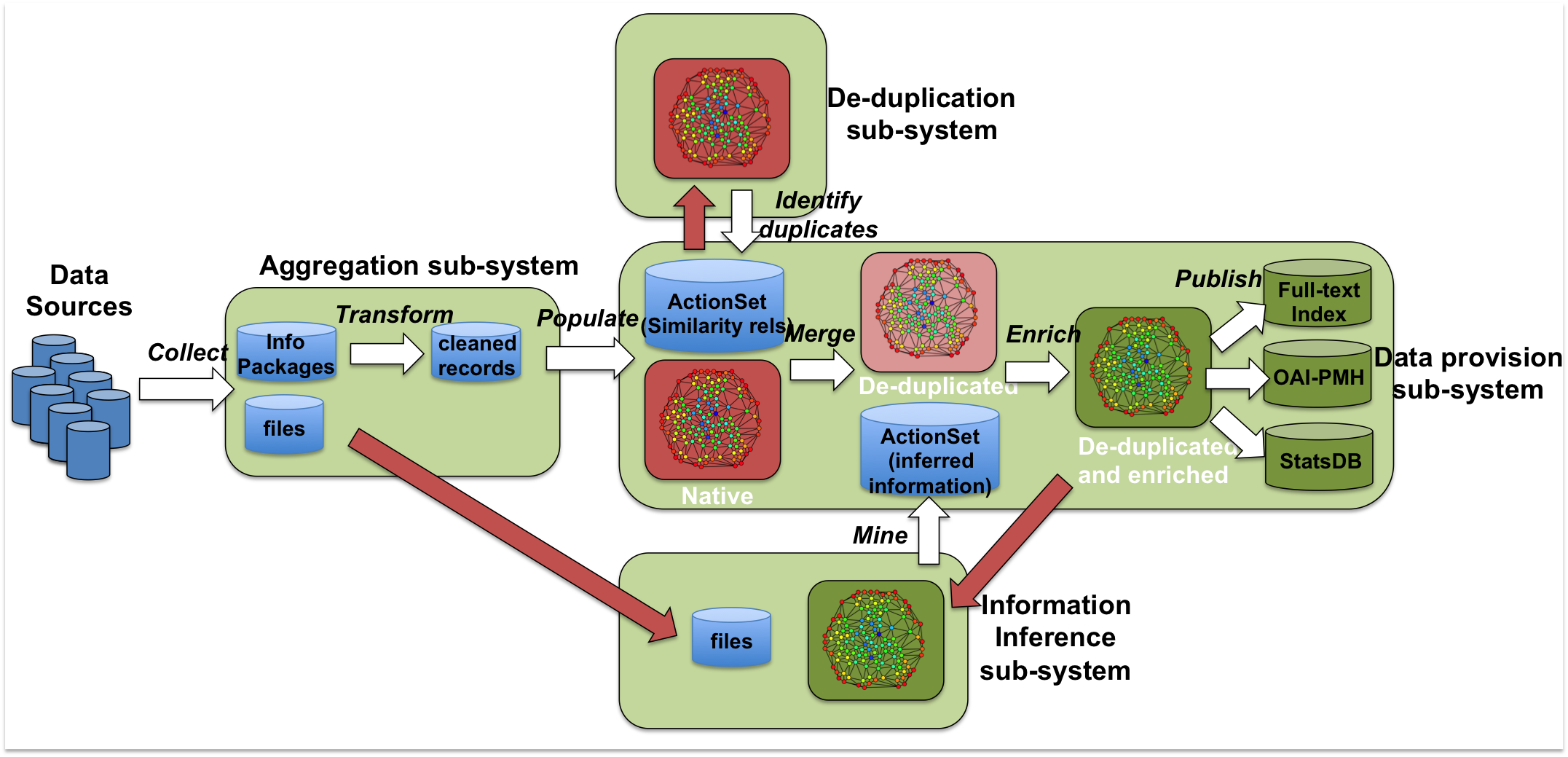
Figure 1 OpenAIRE2020 infrastructure sub-systems.
Updated by Paolo Manghi about 11 years ago · 6 revisions